
As we know, Python has quite a “not-so-good” reputation of performing well. The biggest reason for that is Python being an interpreted language, which means the code is converted into binary (executable form) during the run time. So, many people consider it a “scripting” language just like PHP and JavaScript. But is it fast enough?
Over the years, Python interpreter evolved a lot, also because of the pressure enforced from the higher usage all over the spectrum of programming, data science even including cloud computing. However, you still need to write better code to get the maximum out of the Python interpreter and here are some tips you can increase the speed of your Python code.
Sometimes you may have to write less readable code in order to achieve better performance. You better be ready for some badass coding! It’s your responsibility for finding a balance between high performing vs well-structured and readable code.
Here are what’s in this article.
- List Comprehension
- Inbuilt Function
- Generators
- Pandas
- Multi-Processing
Comprehension
List comprehensions provide a concise way to create lists.
Python Documentation
This is an easy way of creating a new list using another data set we already have by performing an operation on each element of it. [1]
Example:
# Approach 1 : Iterative
x = range(0, 1000000)
y = []
for i in x:
y.append(i**2)The above code can be re-written using list comprehensions like this.
# Approach 2 : Comprehension
x = range(0, 1000000)
y = [i**2 for i in x]The above solution not just looks neat, but runs way faster than we imagine. For example, here are the average run times (from 100 runs) of two approaches.
Iterative = 138.61872 milliseconds
Comprehension = 49.27044 millisecondsAs you can see, the second approach is more than 2.5 times faster than the first naive approach.
Here are some more examples of using comprehension.
# contains squares using all the numbers in x
new_dict = {i: i**2 for i in x}
# only contains squares using even numbers in x
even_dict = {i: i**2 for i in x if i % 2 == 0}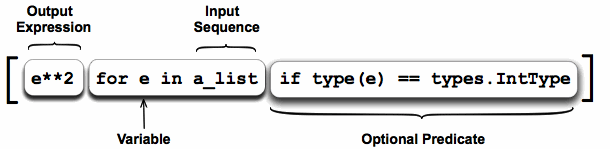
Inbuilt functions
If you need to do something, there probably is a Python function for it.
And these functions are almost always faster than whatever you’ll write in Python. One of the main reasons is those functions are written in an optimized way (usually C language).
Here is an example of an average (of 100) run times when creating a new list from a given list with 100,000 elements. (Check the source code in this Gist.)
I compared the runtime of:
1. Iterating the list
2. Using list comprehension with an inline code
3. Using list comprehension with a function call
4. Using map function
And the results are astonishing!
Iterating a list: 39767570.0 nanoseconds List Comp. with inline code: 31711280.0 nanoseconds List Comp. with function call: 39232530.0 nanoseconds Using map function: 4240.0 nanoseconds
If you can see, using the map() function is almost 7500 times faster than using list comprehension with inline code (fastest among the rest). One of the major reasons for that is the map() function has lazy evaluation [2] properly. It means the values are only evaluated when they’re needed (similar to a generator explained in the next section). So it only creates a mapping between the elements and the evaluation function. So, your program will be more responsive.
Check the complete list of inbuilt functions in the official documentation.
Now you’d be wondering, why did I suggest List Comprehension as an optimization. List comprehension can be used when you need to filter elements from an existing list. It won’t perform well if you need to manipulate elements. So, you have to choose which approach to use depending on your requirements.
Generators
You may already be using this (knowingly or unknowingly) when you use the keyword yield.
A Generator is a simpler way of creating iterators.
In simple terms, a generator function will return an iterator object, which you can later iterate (i.e. inside a for loop). We will talk more details about generators in a separate article, but for now, let’s talk about how we can use them to increase the performance of our code.
Check the following piece of code.
# This is a normal function
def fun():
values = []
for i in range(0, 5):
print("Function", i)
values.append(i)
return values
# This is a generator
def gen():
for i in range(0, 10):
print("Generating", i)
yield i
f = fun()
g = gen()
print("f is a", type(f))
print("g is a", type(g))
for val in f:
print("Printing function", val)
for val in g:
print("Printing generator", val)The output will be:
Function 0 Function 1 Function 2 Function 3 Function 4 f is a <class 'list'> g is a <class 'generator'> Printing function 0 Printing function 1 Printing function 2 Printing function 3 Printing function 4 Generating 0 Printing generator 0 Generating 1 Printing generator 1 Generating 2 Printing generator 2 Generating 3 Printing generator 3 Generating 4 Printing generator 4
If you check the output of the normal Python function, the result is obvious. When we call fun(), it will first generate the list object (while printing Function i) and gets assigned to f. Then over each iteration, it will print Printing function i.
The execution is a bit different in the generator, and that’s why it is in this article. It does NOT execute the code inside the definition unless you iterate through the result (the generator object). So, g = gen() is merely a function to create the generator object. For each iteration usage of the generator, it will execute one iteration of the function it’s related to. This means the piece of code will be executed only when a new value is assigned to the iterating variable in the for loop. That’s why we see Generating i and Printing generator i alternatively.
And how can we use it better? Imagine, we make an API call instead of this print() statement (inside fun() and gen() definitions). In the first approach, it will wait until all the API calls are made and the list is created. It will be very slow if we have a lot of API calls to make. And also, note that the list containing the results is created when we call fun() and it can consume a lot of memory. However, when using the generator, the items are consumed one by one and it will only hold one element in the memory at a given time unless you add it to another list.
Note: You cannot reuse the same generator object twice. If you need to iterate again, you need to get a new generator object by calling fun() again.

Pandas
Many people use Python for Data Science tasks because it’s very easy to write code and we can focus more on the logic. Because Python is not the fastest programming language, it struggles a lot when we need to do CPU or Memory intensive tasks. Then, Pandas comes into the rescue!

pandas is an
https://pandas.pydata.org/open source , BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
If you’re dealing with a lot of data, either to manipulate them or even analyze them, Pandas is the way to go. However, if you have a massive amount of data (i.e. 100s of GBs). If you have a lot more data, you can use a distributed solution such as Spark. Pandas
I’m not going to go deep on how you can use Pandas is specific uses, but I will show some stats of how fast it can be.
(Read more
To load a JSON file of 1.34GB, Pandas only takes around 113.956 seconds (~ 1.89 minutes) on average (in 5 rounds). If you load it using a normal python script, it takes around 52.271 seconds (around 0.9 minutes). If you compare the timing, it seems Pandas are slower in loading the files. The reason is, it takes some time to generate the internal data structures (Data Frames). But if you want to complex joins and filtering on multiple data sets, it will be much faster.
In summary, Pandas are used not just for data analytics tasks but also for moving and processing huge amounts of data. For instance, we have our failure recovery scripts in Python which read two sources to compare the difference and then write a portion of the diff to another data store.
However, there is another tool called Apache Arrow getting some attention, which claims to fix many of the issues Pandas have. It might also be interesting to take look into that. But not now! Until then, you can read this nice article.
Multi-Processing
Another approach to improve your task is to enable your code to run in parallel. However, multi-threaded programs suffer from GIL (Global Interpreter Lock) which allows only one (CPU bound) thread to run simultaneously. It ruins the whole concept of Multi-threading but this limitation is only there in the CPython implementation where the older C-libraries were incapable of handling shared resources properly. However, if you’re using other implementations of the Python interpreter, you still can benefit from multiple threads. Regardless, Multi-Processing can increase the performance a lot.

One important thing to remember is, unlike threads, processes do NOT share memory. If you need to share information between processes, you need to use IPC mechanisms such as sockets. However, the Python multiprocessing module provides a lot of utilities to wrap these functions. There are sharable Queues such as multiprocessing.Queue, multiprocessing.JoinableQueueand a Manager service to create sharable data structures.
Check this GitHub Gist for a sample multi-process program in Python.
These are only 5 things you can do to improve your code. But there are more!!!
Read more things here: https://wiki.python.org/moin/PythonSpeed/PerformanceTips
References
[1] Read more at https://docs.python.org/3/tutorial/datastructures.html#list-comprehensions
[2] https://www.jakubkonka.com/2012/09/02/lazy-evaluation-python.html

